SQLD 2과목 PART2. SQL 활용 완벽 정리(2024 신유형 반영) 유튜브 참조
https://youtu.be/EXx6fjxycSY?si=LDA1D5zpCfGQjiBs
TOP N 쿼리
- https://work-01.tistory.com/394 참조
- 조회결과 상위 N개 추출
- 문법
TOP(N) [PERCENT] [WITH TIES]- 쿼리 결과 집합에서 처음 expression%의 행만 반환
- WITH TIES : 동일 수치의 데이터를 추가로 더 추출하는 옵션 (ORDER BY절 지정했 때만 가능)
- 예제
SELECT TOP(2) ENAME, SAL
FROM EMP
ORDER BY SAL DESC;- 사원 테이블에서 급여가 높은 2명을 내림차순으로 출력
SELECT TOP(2) WITH TIES ENAME, SAL
FROM EMP
ORDER BY SAL DESC;- 사원 테이블에서 급여가 높은 2명을 내림차순으로 출력하는데, 같은 급여를 받는 사원이 있으면 같이 출력
- 잘못사용 예제 (TOP N 미사용)
SELECT ENAME, SAL
FROM EMP
WHERE ROWNUM <4
ORDER BY SAL DESC;- 위 예제를 실행 결과, 나온 3명은 급여가 상위인 3명을 출력한 것이 아니라
급여 순서에 상관없이 무작위로 추출된 3명에 한해서 급여를 내림차순으로 정렬한 것이라 x
- TOP N을 사용하지 않을거라면 FROM절에서 서브쿼리(인라인뷰)로 데이터 정렬 후 사용해야 함
SELECT ENAME, SAL
FROM (SELECT ENAME, SAL
FROM EMP
ORDER BY SAL DESC)
WHERE ROWNUM <4 ;
정규표현식
- 문자열의 공통된 규칙을 보다 일반화 하여 표현하는 방법
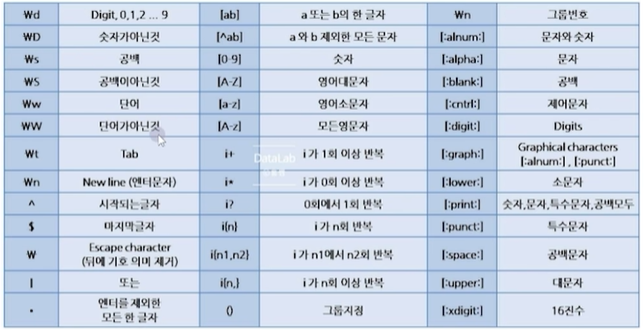
- 단어 : 특수문자 제외, _(언더바)는 단어
- \d : 숫자 한자리 (= [ [ : digit ] ] )
- \W : _제외 모든 특수문자 (= [ [ : punct ] ] )
REGEXP_REPLACE
- 정규식 사용해 문자열 치환
- 문법
(대상, 찾을문자열, [바꿀문자열], [검색위치], [발견횟수], [옵션] )- 바꿀 문자열 생략 시 문자열 삭제처리
- 검색위치 생략 시 1
- 발견횟수 생략 시 0 (모든 것 치환)
- 옵션
- c : 대소를 구분하여 검색
- i : 대소를 구분하지 않고 검색
- m : 패턴을 다중라인으로 선언 가능

- \ ( . + \ ) : ()안 엔터 제외 모든 값
REGEXP_SUBSTR
- 정규식 표현식을 사용한 문자열 추출
- 문법
REGEXP_SUBSTR(대상, 패턴, [검색위치], [발견횟수], [옵션], [추출그룹])- 검색위치 생략 시 1
- 발견횟수 생략 시 1
- 추출그룹은 서브패턴 추출 시 그 중 추출할 서브패턴번호
- 옵션은 위와 동일
- 예제 - 전화번호 분리
SELECT TEL,
REGEXP_SUBSTR(
TEL, -- 원본
'(\d+) \) (\d+) - (\d+)' , -- 패턴 (+서브패턴)
1, -- 시작위치
1, -- 발견횟수
null, -- 옵션
1 -- 추출할 서브패턴(그룹) 번호
) AS 지역번호
FROM STUDENT;=> 서브패턴 번호 1로 지정했으니 TEL이 062)123-4567이면 결과값은 062가 나옴
- 추출할 패턴번호 쓰려면 앞의 옵션들도 모두 작성해야함.
- 사용할 옵션 없을 시 NULL가능
REGEXP_INSTR
- 특정 패턴의 시작위치 반환
- 문법
REGEXP_INSTR(원본, 찾을 문자열, [시작위치], [발견횟수], [옵션])- 시작위치 생략 시 처음부터 확인(기본값 : 1)
- 발견횟수 생략 시 처음 발견된 문자열 위치 리턴
- 위와 옵션 동일
- 예제
SELECT REGEXP_INSTR('500 ORACLE PARKWAY, REDWOOD SHORES, CA',
'[^ ]+', 1, 2) AS "REGEXT_INSTR" -- 두번째로 찾은 공백없이 이어진 단어의 시작위치
RESULT => 5- [^ ] + : 공백 없이 이어져있는 단어(숫자,문자,특수문자)
- 두번째 단어인 ORACLE의 시작위치는 5
REGEXP_LIKE
- 주어진 문자열에서 특정 패턴을 갖는 경우 반환
(WHERE절만 사용 가능)
- 문법
REGEXP_LIKE(원본, 찾을문자열, [옵션])- 옵션 위와 동일
- 예제
SELECT *
FROM PROFESSOR
WHERE REGEXP_LIKE(ID, '\D$'); -- ID값이 숫자로 끝나는 정보 출력
REGEXP_COUNT
- 주어진 문자열에서 특정 패턴의 횟수를 반환
- 문법
REGEXP_COUNT(원본, 찾을문자열, [옵션])
- 예제
SELECT ID,
REGEXP_COUNT(ID, '\d') AS RESULT1, -- 한자리 숫자의 개수 반환
REGEXP_COUNT(ID, '\d+') AS RESULT2 -- 연속된 숫자 개수 반환
FROM PROFESSOR;- ID가 angel1004 일때 result1 = 4, result2 = 1
'SQLD' 카테고리의 다른 글
| [SQLD 공부] 1과목 정리 (0) | 2024.05.24 |
|---|---|
| [SQLD 공부] 39회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.22 |
| [SQLD 공부] 2024년 변경과목 공부(2과목 - PIVOT, UNPIVOT) (0) | 2024.05.22 |
| [SQLD 공부] 38회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.21 |
| [SQLD 공부] 35회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.21 |



