참고 : https://yunamom.tistory.com/237
위 블로그에서 SQLD 기출문제를 열심히 돌리며 한글로 정리하다가
어차피 정리할 바에 블로그에도 쓰면 어디서든 볼 수 있으니 좋겠다는 생각이 들었다. 후후
열심히 업로드 해봐야지
11. 삭제
- DROP : 구조, 데이터 전체 삭제
- TRUNCATE : 구조 유지, 데이터만 전체 삭제
- DELETE : 원하는 데이터만 삭제, 복구가능, 데이터 안줄음
12. ORDER BY 숫자
- 해당 숫자 = SELECT절에서 언급한 컬럼 순서
13. Procedure, Trigger

16. WHERE절에 별도 조건절이 없을 경우, NESTED LOOP JOIN이 무조건 좋은 것은 아님

17. SUM NULL
- SUM(COL1+COL2+COL3+COL4) : 한 행씩 다 더하는데 NULL이 있으면 NULL
- SUM(COL1)+SUM(COL2)+SUM(COL3)+SUM(COL4) : NULL빼고 다 더하기
22. 집계함수
- ROLLUP : 인수 순서중요(계층적), ORDER BY로 정렬
- CUBE : 모든 값에 다차원집계 생성, 시스템에 많은 부하
- GROUPING SETS : 인수 순서 무관(평등)
30. UPDATE -> CREATE -> ROLLBACK 시 SQL SERVER/ORACLE 차이
- ORACLE : DDL(CREATE, ALTER, DROP, TRUNCATE, RENAME) 시 커밋되므로,
- CREATE 취소X, UPDATE만 진행
- SQL SERVER : AUTO COMMIT을 꺼두면 UPDATE, CREATE 모두 취소, 테이블 생성 X
36.
CREATE TABLE 주문 (
C1 NUMBER(10),
C2 DATE,
C3 VARCHAR(10),
C4 NUMBER DEFAULT 100
);
INSERT INTO 주문 (C1,C2,C3) VALUES (1, SYSDATE, 'TEST1');CREATE TABLE 시 DEFAULT 값을 지정한 컬럼도 INSERT 시에 VALUES에 적어주어야함.
37. ORDER BY
- ASC : 오름차순
- DESC : 내림차순
- 정렬할 컬럼을 SELECT절에 명시하지 않아도 됨
- null : oracle은 가장 큰 값, sql server는 가장 작은 값으로 취급하여 정렬함
- ORDER BY 1, COL1 과 같이 숫자와 컬럼을 혼용하여 사용할 수 있음
41. 집합연산자
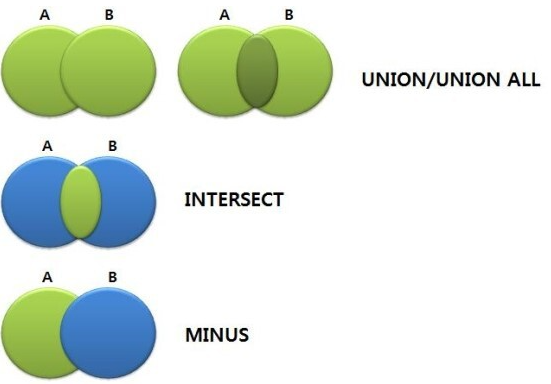
- UNION (합집합) : 중복X 결과의 합
- UNION ALL (합집합) : 중복O 포함한 결과의 합
- INTERSECT (교집합) : 양쪽 모두 포함된 행
- 차집합 : MINUS(오라클), EXCEPT(SQL서버) - 첫 번째에서 두 번째를 제외한 나머지
44. 계층구조
- start with로 지정된 값은 order by에 걸리지 않음(첫번째 행 제외)
47. with절
- 서브쿼리를 with절로 정리가능, 임시테이블로 생각해도 무방함

WITH WITH_TAB (last_name, EMP_ID, MGR_ID, sum_salary )
AS (
SELECT last_name,EMPLOYEE_ID,MANAGER_ID, salary
FROM HR.EMPLOYEES
WHERE MANAGER_ID IS NULL
UNION ALL
SELECT a.last_name, a.EMPLoYEE_ID, a.MANAGER_ID, a.salary + b.sum_salary
FROM HR.EMPLOYEES A, WITH_TAB B
WHERE B.EMP_ID = A.MANAGER_ID
)
SELECT SUM_SALARY FROM WITH_TAB
WHERE EMP_ID = 105;
49. NTILE
- 전체 건수를 인수값으로 N등분
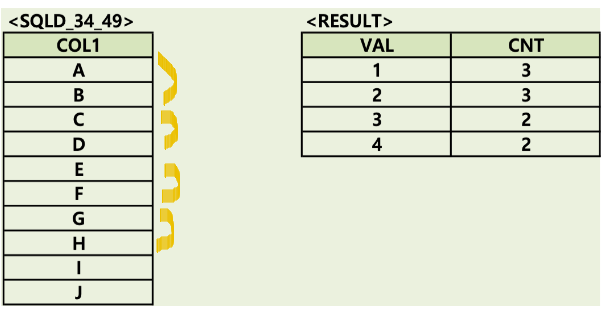
SELECT VAL, COUNT(*) AS CNT
FROM (
SELECT NTILE(4) OVER (ORDER BY COL1) AS VAL
FROM SQLD_34_X7
)
WHERE 1=1
GROUP BY VAL
ORDER BY 1;
50. LAG
- LAG(컬럼명 A, n) : n번째 이전 행의 A컬럼 값을 가져옴

SELECT EMPLOYEE_ID,
DEPARTMENT_ID,
LAST_NAME,
SALARY,
LAG(SALARY, 2) OVER(PARTITION BY DEPARTMENT_ID ORDER BY SALARY)
AS BEFORE_SALARY
FROM SQLD_50
WHERE EMPLOYEE_ID < 190;
'SQLD' 카테고리의 다른 글
| [SQLD 공부] 2024년 변경과목 공부(2과목 - 정규표현식, TOP N 쿼리) (0) | 2024.05.23 |
|---|---|
| [SQLD 공부] 39회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.22 |
| [SQLD 공부] 2024년 변경과목 공부(2과목 - PIVOT, UNPIVOT) (0) | 2024.05.22 |
| [SQLD 공부] 38회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.21 |
| [SQLD 공부] 35회 기출문제 오답 및 모르는 것 정리 (0) | 2024.05.21 |



